Introduction to this article
This article derives the memory barrier from a hardware perspective. This is not an exhaustive manual for memory barriers, but the knowledge is helpful for understanding RCU . This is not a separate article. This is the second article in the series " Xie Baoyou: Deep Understanding Linux RCU ". Preface:
Xie Baoyou: Deep understanding of one of the Linux RCUs - from the hardware
About the Author
Xie Baoyou has been working on the first line of programming for 20 years, of which nearly 10 years worked on the Linux operating system. During his work in ZTE's operating system product department, he was the telecom-grade embedded real-time operating system with the participation of the chief technical officer, and won the industry's highest award----China Industrial Award.

At the same time, he is also the translator of "In-depth Understanding of Parallel Programming". The author Paul E. McKeney is the IBM Linux Center leader, Linux RCU Maintainer. The "In-depth Understanding of RCU" series of articles has compiled Paul E. McKeney's related work, hoping to help readers to understand more deeply understand the very difficult module in the Linux kernel - RCU.
Contact information:
Mail:
WeChat: linux-kernel

Manuscript collection
You are welcome to contribute to Linuxer and win any technical books for sale in the People's Posts and Telecommunications Asynchronous Community. You can pick it up, details: Linuxer-"Linux Developer's own media" first month manuscript admission and gift list
Linuxer-"Linux Developer's own media" second month manuscript admission and gift list

First, what are the shortcomings of memory Cache?

In the previous article we talked about memory Cache and described the typical Cache coherency protocol MESI . The fundamental purpose of Cache is to resolve memory and CPU speeds by up to two orders of magnitude. A computer system containing a Cache , whose structure can be simply represented as the following figure:
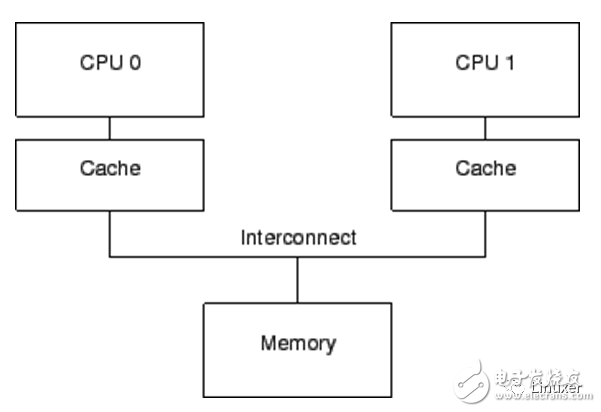
There are only Cache computer systems, and it also has the following problems:
1 , Cache speed, although greatly improved than memory, but still several times slower than the CPU .
2. When "warmup cache miss ", "capacity miss ", "associativity miss " occurs, the CPU must wait to read data from the memory, and the CPU will be in a Stall state. Its wait time may reach several hundred CPU instruction cycles.
Obviously, this is something that modern computers can't afford :)
Second, Write buffer is to solve what problem?
If the CPU is just executing a statement like foo = 1 , it doesn't need to read foo's current value from memory or cache . Because no matter what the current value of foo is, it will be overwritten. In a system with only Cache , operations such as foo = 1 will also form a write pause. Naturally, CPU designers should think of adding a level 1 cache between the Cache and the CPU . Since such a cache is mainly responsible for Cache Miss caused by a write operation , and the cached data is related to a write operation, the CPU designer names it "Write buffer ". The adjusted structure is as follows (the store buffer in the figure is the write buffer):

By adding these Write buffers , the CPU can simply put the data to be saved into the Write buffer and continue to run without actually waiting for the Cache to read the data from memory and return .
These Write buffers are local to a particular CPU . Or in a hardware multi-threaded system, it is local to a particular core. In either case, a particular CPU only allows access to the Writebuffer assigned to it . For example, in the above figure, CPU 0 cannot access the storage buffer of CPU 1 , and vice versa.
Write buffer further improves system performance, but it also causes some confusion for hardware designers:
The first trouble: violation of its own consistency.
Consider the following code: The variables " a " and " b " are both initialized to 0 , contain the variable " a " cache line, originally owned by CPU 1 , and the cache line containing the variable " b " is initially owned by CPU0 :
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
No software engineer wants the assertion to be triggered!
However, if you use the simple system structure shown above, the assertion will indeed be triggered. The key to understanding this is: a is initially owned by CPU 1 , while CPU 0 stores a new value of a in the Write buffer of CPU 0 when a = 1 is executed .
In this simple system, the sequence of events that trigger an assertion might be as follows:
1 . CPU 0 starts executing a = 1 .
2 . CPU 0 looks for "a" in the cache and finds that the cache is missing.
3 . Therefore, CPU 0 sends a " read-invalidate message " message to obtain an exclusive cache line containing "a" .
4 . The CPU 0 "a" recorded on the memory buffer.
5 . The CPU 1 receives a " read invalid " message, which responds to this message by sending cache line data and removing data from its cache line.
6 . CPU 0 starts executing b = a + 1 .
7 . CPU 0 cache line is received from the CPU 1, it still has a "0" in the "a" value.
8 . CPU 0 reads the value of "a" from its cache and finds that its value is 0 .
9 . CPU 0 applies the entry in the store queue to the most recently arrived cache line, setting the value of "a" in the cache line to 1 .
10 . CPU 0 increments the previously loaded "a" value by 0 and stores the value in the cache line containing "b" (assuming it is already owned by CPU 0 ).
11 . CPU 0 executes assert(b == 2) and causes an error.
In response to this situation, hardware designers have given the necessary sympathy to software engineers. They will make a slight improvement to the system, as shown below:

In the adjusted architecture, each CPU will consider (or sniff) its Writebuffer when it performs a load operation . Thus, in step 8 of the previous execution sequence, the correct value of 1 will be found for the "a" in the storage buffer , so the final "b" value will be 2 , which is what we expect.
The second problem with Write buffer is that it violates the global memory order. Consider the following code sequence where the initial values ​​of the variables " a ", " b " are 0 .
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
Suppose CPU 0 executes foo() , CPU1 executes bar() , and further assumes that the cache line containing " a " is only in the cache of CPU1 , and the cache line containing " b " is owned by CPU0. Then the order of operation may be as follows:
1 . CPU 0 executes a = 1 . The cache line is not in the cache of CPU0 , so CPU0 puts the new value of " a " into the Write buffer and sends a "read invalid" message.
2 . CPU 1 executes while (b == 0) continue , but the cache line containing " b " is not in its cache, so it sends a "read" message.
3 . CPU 0 executes b = 1 and it already owns the cache line (in other words, the cache line is either already " modified " or in the " exclusive " state), so it stores the new " b " value into its cache line. in.
4 . CPU 0 receives the "read" message and sends the value of the most recently updated " b " in the cache line to CPU1 while setting the cache line to the " shared " state.
5 . CPU 1 receives the cache line containing the " b " value and writes its value to its cache line.
6 . CPU 1 now ends executing while (b ==0) continue because it finds that the value of " b " is 1 , and it starts processing the next statement.
7 . The CPU 1 executes assert(a == 1) and, since the CPU 1 is operating at the value of the old " a ", the assertion fails.
8 . The CPU 1 receives the "read invalid" message and sends a cache line containing " a " to CPU 0 , while in its cache, the cache line becomes invalid. But it is too late.
9 . CPU 0 receives the cache line containing " a " and saves the data of the storage buffer to the cache line in time, and the assertion failure of CPU1 is victimized by the cache line.
Please note that the "memory barrier" has been faintly revealing its sharp claws here! ! ! !
Third, what is the problem with invalid queues?
One wave is not flat, another wave is coming back.
The complexity of the problem is not only in the Writebuffer , because only the Write buffer , the hardware will also form a serious performance bottleneck.
The problem is that each core's Writebuffer is relatively small, which means that a CPU that performs a small sequence of memory operations will quickly fill its Writebuffer . At this point, the CPU must wait for the Cache refresh operation to complete before it can continue execution to clear its Write buffer .
Clearing the Cache is a time consuming operation because MESI messages ( making invalid messages ) must be broadcast between the CPUs in which they are located , and wait for responses to these MESI messages. In order to speed up the MESI message response speed, the CPU designer added an invalid queue. That is to say, the CPU will temporarily store the invalid message, and when the invalid message is sent , the value in the Cache is not invalid. Instead, wait for the delay to invalidate the operation when appropriate.
The following figure shows the system structure that adds invalid queues:
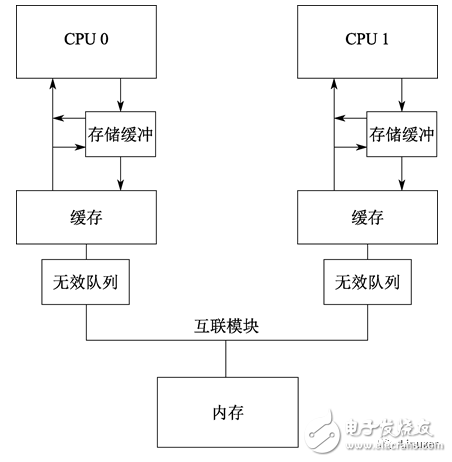
Putting an entry into the invalid queue is actually a promise by the CPU to process the entry before sending any MESI protocol messages associated with the cache line . In the case that the Cache competition is not too intense, the CPU will do this very well.
The problem with invalid queues is that the other CPUs have been invalidated before the Cache is actually invalidated. This is somewhat of a deception. However, modern CPUs are really designed this way.
This fact brings an extra chance of memory out of order, see the following example:
Suppose " a " and " b " are initialized to 0 , " a " is read-only ( MESI " shared " state), and " b " is owned by CPU 0 ( MESI " exclusive " or " modified " state). Then assume that CPU 0 executes foo() and CPU1 executes bar() with the following code fragment:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
The sequence of operations may be as follows:
1 . CPU 0 executes a = 1 . In CPU0 , the corresponding cache line is read-only, so CPU 0 puts the new value of " a " into the storage buffer and sends an "invalid" message, in order to make the corresponding cache line in CPU1 's cache. Invalid.
2 . CPU 1 executes while (b == 0) continue , but the cache line containing " b " is not in its cache, so it sends a "read" message.
3 . CPU 1 receives the "make invalid" message for CPU 0 , queues it, and immediately responds to the message.
4 . CPU 0 is received from the response message of the CPU 1, so it is assured by the row of 4 smp_mb (), is moved from the storage buffer "a" value to the cache line.
5 . CPU 0 executes b = 1 . It already owns this cache line (that is, the cache line is already in the " modified " or " exclusive " state), so it stores the new value of " b " in the cache line.
6 . CPU 0 receives the "read" message and sends a cache line containing the new value of " b " to CPU1 , while in its own cache, the tag caches the behavior " shared " state.
7 . CPU 1 receives the cache line containing " b " and applies it to the local cache.
8 . CPU 1 can now complete while (b ==0) continue because it finds the value of " b " as 1 , and then processes the next statement.
9 . The CPU 1 executes assert(a == 1) and, because the old " a " value is still in the cache of the CPU 1 , it is caught in an error.
10 . Despite the error, CPU 1 processes the "make invalid" message that has been queued and (late) refreshes the cache line containing the " a " value in its own cache.
Fourth, the memory barrier
Since hardware designers introduce additional memory out-of-order issues through Write buffers and invalid queues, software engineers should be provided with some way to solve this problem. Even the corresponding solution will plague the software engineer.
The answer is the memory barrier. For the senior engineers of the Linux kernel, this answer is also quite heavy, it is too torturous :)
Let's take a look at the example of triggering assertions in the Write buffer section, how to modify them.
In that case, the hardware designer can't directly help us because the CPU has no way of identifying those associated variables ( a and b in the example ), let alone how they relate. Therefore, the hardware designer provides memory barrier instructions to allow the software to tell the CPU the existence of these relationships. The program must be modified to include a memory barrier:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
The memory barrier smp_mb() will cause the CPU to flush the previous Write buffer before flushing the subsequent cache line (including the cache line of b ) . The actions the CPU might take before proceeding with processing are:
1. Simply pause until the storage buffer becomes empty;
2. It is also possible to use a storage buffer to hold subsequent storage operations until all previous storage buffers have been saved to the cache line.
Understanding the second point can help us understand the origin of the word "memory barrier"! !
In the latter case, the sequence of operations might look like this:
1 . CPU 0 executes a=1 . The cache line is not in the cache of CPU0 , so CPU 0 puts the new value of " a " into the store buffer and sends a "read invalid" message.
2 . CPU 1 executes while(b == 0) continue , but the cache line containing " b " is not in its cache, so it sends a "read" message.
3 . CPU 0 executes smp_mb() and marks the entries for all current storage buffers. (That is to say a = 1 this entry).
4 . CPU 0 executes b= 1 . It already has this cache line. (That is , the cache line is already in the " modified " or " exclusive " state), but there is a tag entry in the store buffer. Therefore, it does not store the new value of " b " in the cache line, but instead stores it in the storage buffer. (But " b " is not a tag entry).
5 . CPU 0 receives the "read" message and then sends a cache line containing the original " b " value to CPU1 . It also marks the copy of the cache line as " shared ".
6 . CPU 1 reads the cache line containing " b " and copies it into the local cache.
7 . CPU 1 can now load the value of " b ", but since it finds that its value is still " 0 ", it repeatedly executes the while statement. The new value of " b " is safely hidden in the storage buffer of CPU0 .
8 . The CPU 1 receives the "read invalid" message, sends a cache line containing " a " to CPU 0 , and invalidates its cache line.
9 . CPU 0 receives the cache line containing " a ", replaces the cache line with the value of the store buffer, and sets this line to the " modified " state.
10 . Since the stored " a " is the only entry in the storage buffer marked by smp_mb() , CPU0 can store the new value of " b " into the cache line unless the cache line containing " b " is currently in the " shared " state .
11 . CPU 0 sends an "Invalid" message to CPU 1 .
12 . CPU 1 receives the "make invalid" message, invalidates the cache line containing " b ", and sends an "make invalid reply" message to CPU0 .
13 . CPU 1 executes while(b == 0) continue , but the cache line containing " b " is not in its cache, so it sends a "read" message to CPU0 .
14 . CPU 0 receives the "make invalid reply" message and sets the cache line containing " b " to the " exclusive " state. CPU 0 now stores the new " b " value to the cache line.
15 . CPU 0 receives the "read" message and simultaneously sends a cache line containing the new " b " value to CPU1 . It also marks the copy of the cache line as " shared ".
16 . CPU 1 receives the cache line containing " b " and copies it into the local cache.
17 . CPU 1 is now able to load the value of " b ", since it finds that the value of " b " is 1 , it exits the while loop and executes the next statement.
18 . CPU 1 executes assert(a== 1) , but the cache line containing " a " is not in its cache. Once it gets this cache line from CPU0 , it will use the latest " a " value, so the assertion statement will pass.
As you can see, this process involves a lot of work. Even if something is intuitively a simple operation, an operation like "loading the value of a" will involve a lot of complicated steps.
As mentioned earlier, it is actually a write-side barrier that solves the memory disorder introduced by Write buffer . Next, let's look at the reader's barrier, which resolves the memory out of order that introduces invalid queues.
To avoid errors in the invalid queue example, you should use the read memory barrier again:
The read-side memory barrier instruction can interact with the invalid queue so that when a particular CPU executes a memory barrier, it marks all entries in the invalid queue and forces all subsequent load operations to wait until all marked entries are Save to the Cache of the CPU . Therefore, we can add a memory barrier to the bar function as follows:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
With this change, the order of operations might be as follows:
1 . CPU 0 executes a=1 . The corresponding cache line is read-only in the cache of CPU0 , so CPU0 puts the new value of " a " into its storage buffer and sends an "make invalid" message to flush the corresponding cache line of CPU1 .
2 . CPU 1 executes while(b == 0) continue , but the cache line containing " b " is not in its cache, so it sends a "read" message.
3 . CPU 1 receives the "make invalid" message for CPU 0 , queues it, and immediately responds to it.
4 . CPU 0 receives the response from CPU1 , so it safely moves " a " from its storage buffer to the cache line via the smp_mb() statement on line 4.
5 . CPU 0 executes b= 1 . It already owns the cache line (in other words , the cache line is already in the " modified " or " exclusive " state), so it stores the new value of " b " to the cache line.
6 . CPU 0 receives the "read" message and sends a cache line containing the new " b " value to CPU1 , while in its own cache, the tag caches the " shared " state.
7 . CPU 1 receives the cache line containing " b " and updates it into its cache.
8 . CPU 1 now ends executing while (b == 0) continue because it finds the value of " b " as 1 , which processes the next statement, which is a memory barrier instruction.
9 . CPU 1 must be stalled until it has processed all messages in the invalid queue.
10 . CPU 1 processes the "make invalid" message that has been enqueued, invalidating the cache line containing " a " from its cache.
11 . CPU 1 executes assert(a== 1) , and since the cache line containing " a " is no longer in its cache, it sends a "read" message.
12 . CPU 0 responds to the "read" message with a cache line containing the new " a " value.
13 . CPU 1 receives the cache line, which contains the new " a " value of 1 , so the assertion will not be triggered.
Even with a lot of MESI messaging, the CPU will eventually respond correctly. This section explains why CPU designers must handle their cache coherency optimization operations with extreme care.
But is there really a need for a read-end memory barrier? Prior to assert (), not a cycle it?
Is assert(a == 1) executed before the end of the loop ?
For readers who have doubts about this, you need to add a bit of background on guessing (adventure) execution! You can look at the CPU reference manual. Simply put, in the loop, a == 1 this comparison condition, it is possible that the CPU will preload the value of a into the pipeline. Temporary results are not saved to the Cache or Write buffer , but are temporarily stored in the temporary result registers in the CPU pipeline .
Is this a very counterintuitive? However, this is the case.
Friends who are interested in anti-intuitive things in the CPU world can even look at books on quantum mechanics. Quantum computers really need to understand quantum mechanics. Let the " Schrodinger's Cat " mentioned in the book "In-depth Understanding of Parallel Programming" burn the brain. This cat has already tortured the brains of countless geniuses. In addition to Hawking, there is Einstein's brain!
V. Further thinking about the memory barrier
This article only introduces the memory barrier from the hardware point of view. Its purpose is to better explain RCU in subsequent articles . Therefore, there is no in-depth analysis of the memory barrier. However, for understanding RCU , the knowledge of memory barriers in this article is already ok.
More in-depth thinking includes:
1. The concept of reading barriers, writing barriers, and reading dependency barriers
2. The implementation of barriers and their subtle differences in various architectures
3 , deep thinking about whether the memory barrier is necessary, is it possible to modify the hardware, so that the barrier is no longer useful?
4 , the transitivity of the memory barrier, this is a more subtle and difficult to understand concept in the Linux system.
5. What is the barrier in the single-core architecture to solve? how to use?
6. What kind of synchronization primitive semantics does the barrier use in the kernel synchronization primitive?
a thing that joins together two parts of sth, two vehicles or two pieces of equipment.

Custom Coupling,Coupling Of Encoders,Useful Coupling,Latest Coupling
Yuheng Optics Co., Ltd.(Changchun) , https://www.yuhengcoder.com